
Pydata Amsterdam 2024
This year I visited pydata in Amsterdam. Here are some of the sessions I visited with tutorial links, my brief thoughts on some keynotes, and a programming puzzle that really interested me.
Polars plugin in Rust
Polars is a dataframe library taking the world by storm. It is very runtime and memory efficient and comes with a clean and expressive API. Sometimes, however, the built-in API isn’t enough. And that’s where its killer feature comes in: plugins. You can extend Polars, and solve practically any problem.
Building plugins for polars in Rust. This is a pretty useful idea if there are transformations needed on data that take a very long time to do in a standard python loop. The setup as explained is doable in a very short time even for non-rustaceans.
Building data pipelines with Prefect
Embark on a transformative journey into the realm of data engineering with our 90-minute workshop dedicated to, recently released, Prefect 3. In this hands-on session, participants will learn the ins and outs of building robust data pipelines using the latest features and enhancements of Prefect 3. From data ingestion to advanced analytics, attendees will gain hands-on experience and practical insights to elevate their data engineering skills.
Cadarn/PyData-Prefect-Workshop
This can be a useful tool to keep track of more complex data science or NLP pipelines. This gives some insight in the time each step takes, and gives a gui with useful log views. It’s also possible to schedule runs.
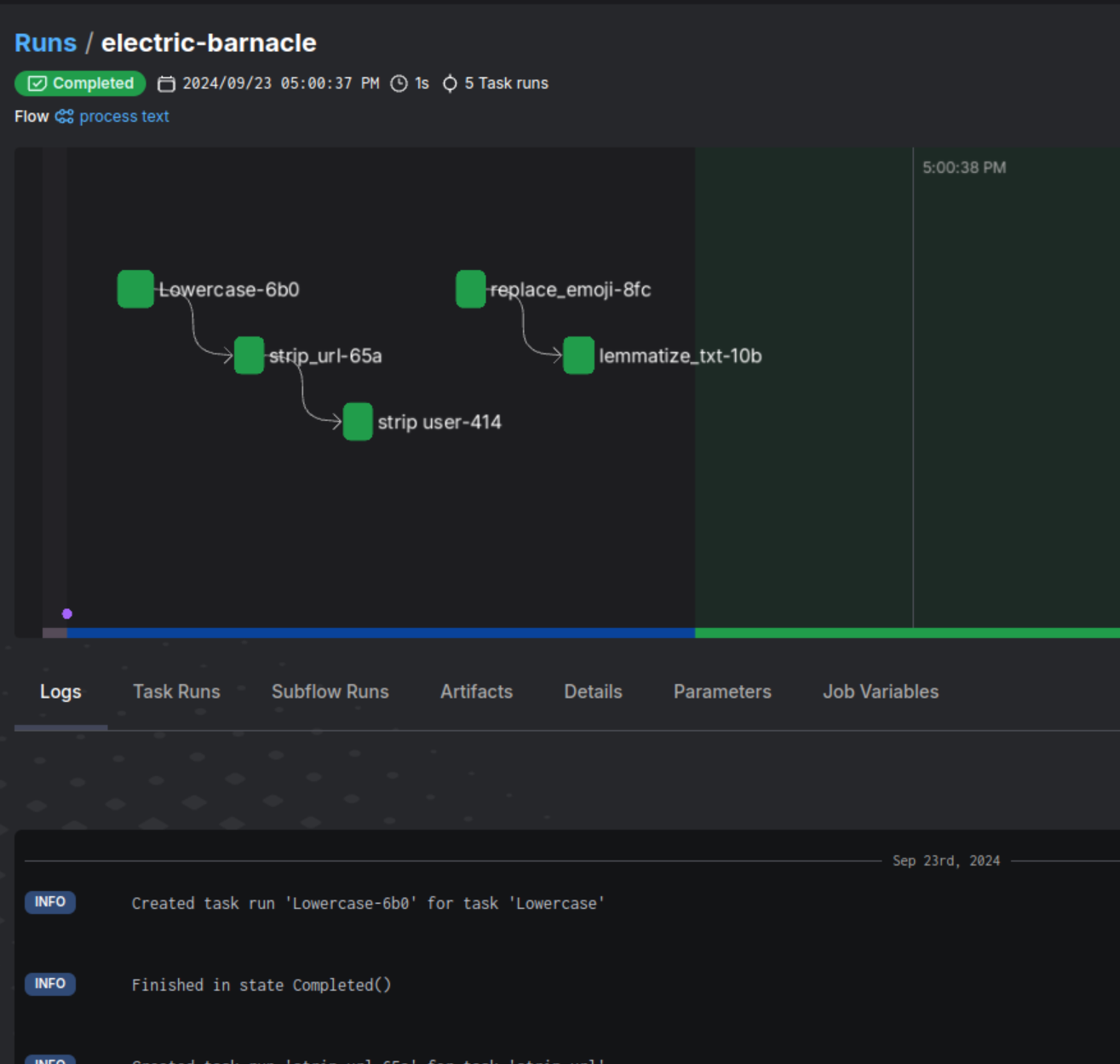
shows the duration of tasks in one flow for one run and some logging
Uplift modeling
Uplift modeling is a cutting-edge approach that goes beyond traditional predictive modeling by estimating the causal effects of treatments on individuals. This makes it the to go framework for personalized marketing, customer retention, and beyond. Our tutorial is designed to provide you with a practical understanding of uplift modeling, complete with real-world Python examples.
bookingcom/uplift-modeling-for-marketing-personalization-tutorial
Probably not useful to the kinds of models I’m usually working on.
Open-source Multimodal AI in the Wild
Merve from Huggingface talked about multi-modal models, and the state of the ecosystem. For me the most interesting parts were about retrieval. Do not use OCR+LLM, but use a vision model instead.
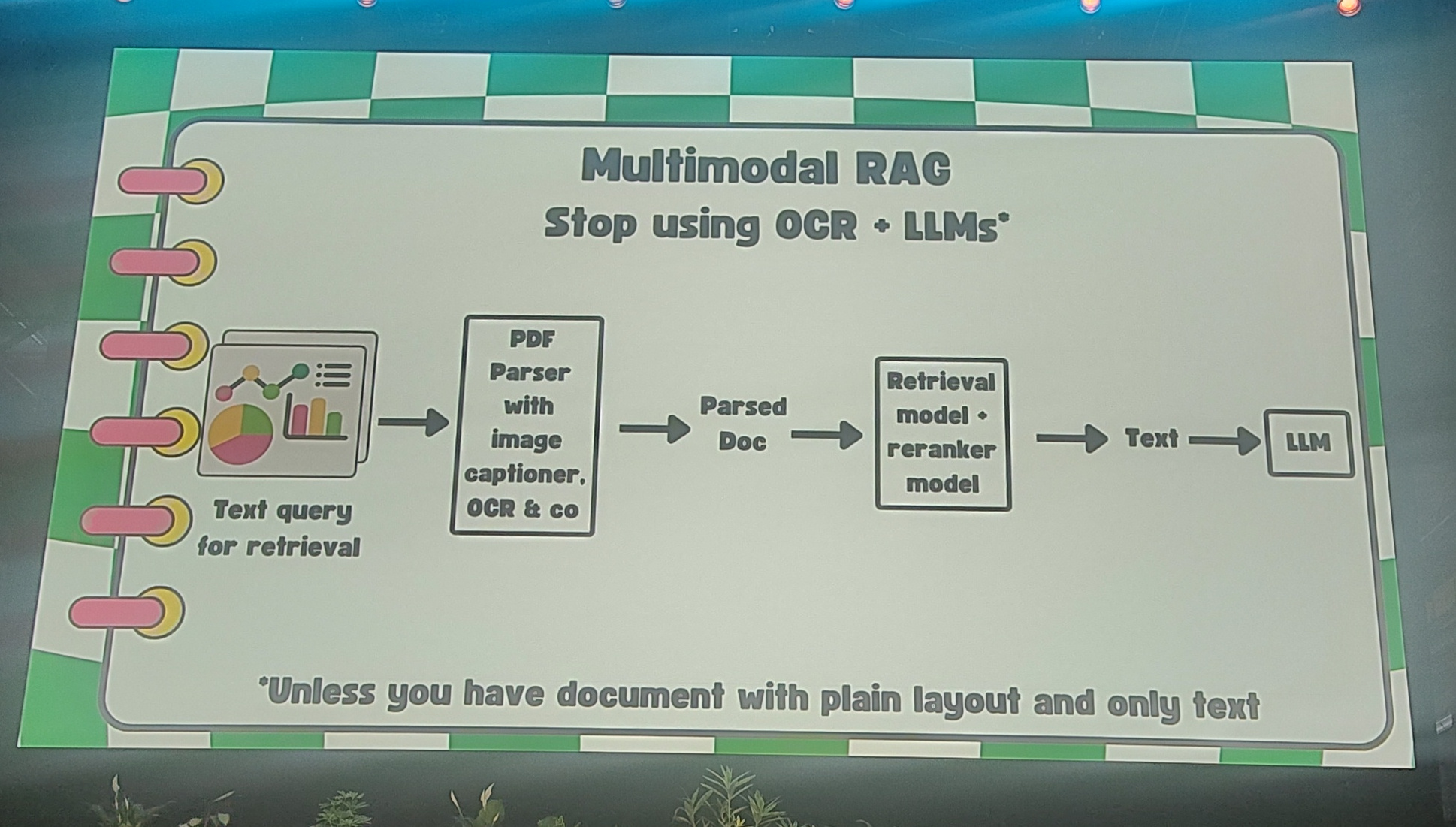
Do not use OCR+LLM

but use a vision model instead
I also plan to check out her project smol-vision
Cyber Resilience Act
The EU Commission is likely to vote on the Cyber Resilience Act (CRA) later this year. The CRA is an ambitious step towards protecting consumers from software security issues by creating a new list of responsibilities for software developers and providers. The Act also creates a new category of actor known as an “Open Source Steward” which we think makes important allowances for public open source repositories
The most interesting part of this presentation for me was this slide. It shows when an open source project is covered by the CRA. 1

Is your open-source project covered?
ING talk
Productionizing generative AI applications in a highly regulated banking environment such as ING comes with a plethora of challenges
Working for ING myself this hits close to home. Impressive nonetheless what they were able to achieve. The part that stuck with me most is where they asked this sequence of questions:
- Who has an LLM application?
- Who has an LLM application in production?
- Who has an LLM application in production in a well regulated industry like government or finance?
The show of hands went down 100%, 10%, 1%.
Another interesting part was the development of architecture starting from a jupyter notebook with a prototype to an actual application in production, and the considerations that requires.
Open-source machine learning on encrypted data
Fully Homomorphic Encryption (FHE) enables computations on encrypted data. It works by adding noise to the input. This enables using remote machines for computations without sacrificing privacy.
pandas dataframes are one-dimensional
James Powell can talk very fast. He claims pandas dataframes are one-dimensional. Usually the columns of a pandas dataframe do not represent a dimension, but instead are index aligned vectors that represent different data.
The Odyssey of Hacking LLMs
An AI expert and a security expert discuss their experience in taking part in a Capture the Flag event (SaTML). They discuss some attack and defense tactics. Some defense tactics like:
- an LLM filter before the main LLM with a prompt to check for suspicious input
- a python code filter after the main LLM to check for leaking of secrets
- an LLM filter after the main LLM with a prompt to check for leaking of secrets.
They then describe a few tactics to get around these including:
- jailbreaking the LLM
- asking the LLM to encode the secret before returning it Their main point is a useful one: if your LLM knows a secret it will get leaked.
Terrible tokenizer troubles in large language models
Huge amounts of resources are being spent training large language models in an end-to-end fashion. But did you know that at the bottom of all these models remains an important but often neglected component that converts text to numeric inputs? As a result of weaknesses in this ‘tokenizer’ component, some inputs can not be understood by language models, causing wild hallucinations, or worse.
If a token is in the dataset that was used to create the tokenizer, but not present in the dataset that was used to train the LLM, it will result in strange behaviour.
Karpathy also talks about this in his tutorial on building a tokenizer.
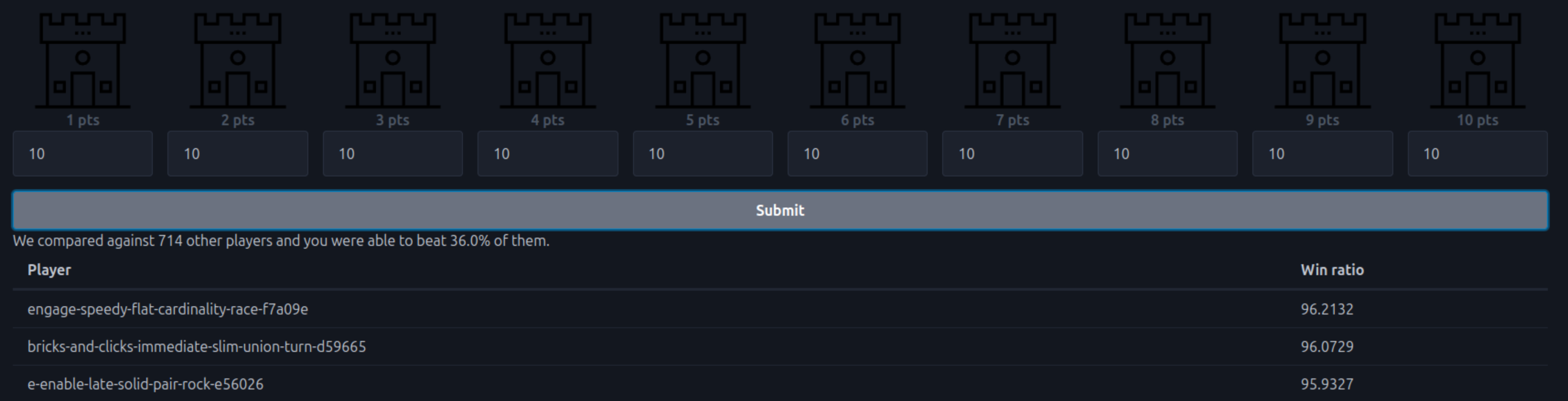
the 10-castles coding challenge
I also got nerdsniped by this problem.
-
Disclaimer: not legal advice. ↩︎