

Highlights from aiGrunn 2025
Table of Contents
I visited the AI conference in Groningen called aiGrunn. As an AI practitioner, I was curious to see what the local AI scene in Groningen is working on. The name of the conference comes from the city of Groningen where the event is hosted, “ai” also means egg in Gronings, so there are a lot of egg references.
Talks
How AI is helping you back on the road
Yke Rusticus from ANWB is presenting how AI techniques fit in to diagnosing car trouble for roadside assistance. He showed different steps in the process of diagnosing and repairing a car where AI could help. From determining if roadside assistance was needed to planning where to send the repair vans. Quite cool to see an application of AI in a different sector than usual, even though the techniques are very similar to what I’m using in my own work.

learnings at the end
The lesson about including the feedback loop early on is one I think is very useful.
Design Patterns for AI Agents in Python
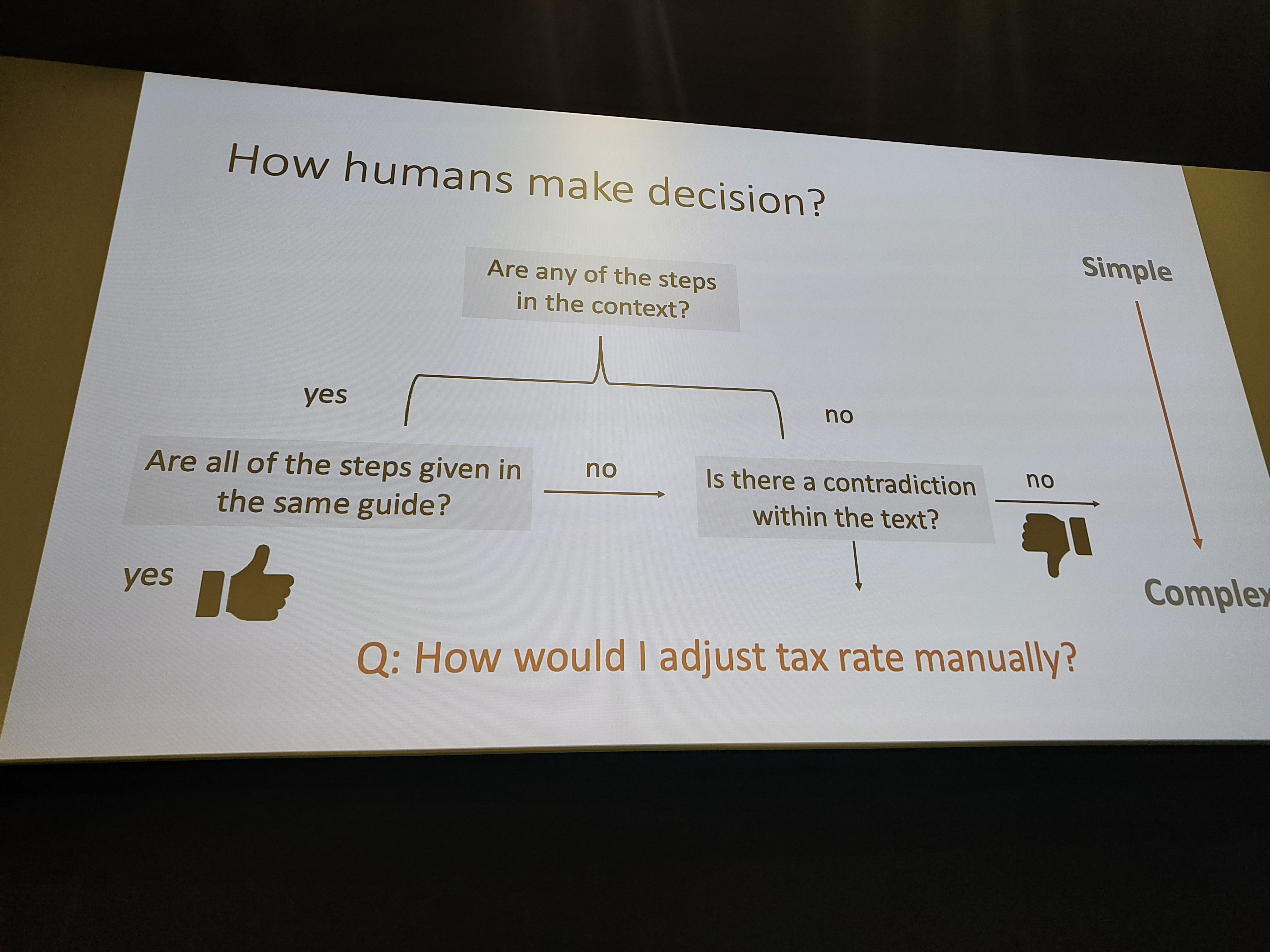
The talk by Arjan was titled “Design Patterns for AI Agents in Python (with Pydantic AI)”, but he ended up not using Pydantic AI. Instead, he focused on the broader design patterns for AI agents. The core of his talk was about declarative versus imperative programming. He argued that a declarative approach is well-suited for LLMs, as it allows you to define the desired outcome and let the LLM figure out the steps to get there. While the talk wasn’t what I expected from the title, it was a good reminder of the importance of fundamental design principles when working with AI.
Speaking to a declaratively designed LLM flow in Gronings
Building Interactive AI Vision Tools in the Browser
Mark Redeman gave a practical talk on building an interactive image annotation tool that runs directly in the browser. He demonstrated how to use OpenCV compiled to WebAssembly (Wasm) to achieve this. A key insight was the importance of optimizing the library size; by manually compiling OpenCV to Wasm, he was able to shrink the size from 9.8 MB to just 2.1 MB, making it much more suitable for web applications. He pointed to the open-source project GETI as a reference, which can be found at https://github.com/open-edge-platform/geti/. One of the highlights was him showing the meta model for segmentation SAM. This model was pretty good at segmenting objects from a single point.
GPT-NL: Developing a Dutch LLM from scratch
Julio and Athanasios talk about data acquisition, and training an LLM from scratch. The goal is to have an LLM with trusted data sources, in theory open weights in the Dutch language. This LLM should be capable of doing tasks that are most relevant to Dutch language. An interesting anecdote was: If you ask an LLM to come up with a children’s story it will most likely come up with superheroes or cowboys because those are frequent in american culture, but it would be cool if the Dutch model would come up with schippers van de kameleon or jip en janneke. I wonder if this approach will be valuable in the future, as it will be hard to compete with the tech giants. But if there are use cases where the American or Chinese models are forbidden from being used, or do not provide the niche properties of a Dutch-first model it might prove useful.
Liar Lair! Assessing the Correctness of LLM Chatbots
This talk tackled the challenging question of how to assess the correctness of an LLM chatbot’s output. The speaker started by defining correctness, breaking it down into three components: relatedness, completeness, and truthfulness. Truthfulness was highlighted as the most critical component.
A key takeaway for me was the suggestion to check if the generated answer includes organization-specific jargon. If it does, it’s more likely that the answer was derived from the correct context. The talk also covered several challenges in assessing correctness, such as when an answer is correct but not the best possible answer, or when the source documentation is outdated. A particularly interesting point was that a model can “hallucinate” a correct answer, meaning it doesn’t refer to any context but is still factually right. This makes the problem of validation even more complex.
Teaching AI to Hunt for Vulnerabilities
Roald Nefs introduces me to the term vibe hacking. He compares the LLM hacking agent to a pig looking for truffels. You still need the human to pick up the truffels and sell them. He shows the architecture for a multi agent setup with one planning agent, and multiple agents that can use tools. They work together on a task list to perform a penetration test of a target. This setup was more a proof-of-concept than a fully realised solution, but was interesting nonetheless.
Some risks include:

The keynote from Michael Biehl was very technical and in-depth, covering traditional AI applied to a few medical problems. It was cool to see what an algorithmically much simpler model can already achieve, even though the statistical analysis following the model training is still quite complex.
Finally during the panel there was a question about European LLMs versus the American and Chinese models. It looks like the development of European models is lagging behind the competition by quite a lot. Berco Beute, the host of the day shared a car analogy to answer this question. The car developed by Americans for an American market where gasoline is cheap, size is not an issue and pollution was also not really a problem. Then the Japanese also gave their own interpretation to the car, taking into account much more their relevant constraints in size, and availability of fuel. He mentioned that the European design of LLMs might follow a similar trajectory in a much more regulated market, taking environmental and energy constraints into account.
Conclusion
It was fun to attend this conference once again. It helps with keeping up to date with the latest tech and seeing what others in the field are doing. The sobering remarks from Michael Biehl about AI hype and how the interest in AI comes and goes were also welcome. I look forward to visiting again next year.