
Aigrunn2024
I visited the AI conference in Groningen called aigrunn. This article has some notes on the sessions I attended. These notes are primarily for my own reference and not very well formatted, sorry!
Going beyond tabular data with graphs
Talk by Chris van Riemsdijk from datanorth about graph neural networks. This talk was about data that can be organised as a graph. Graph Neural Networks called GNN’s transform graphs. The idea is graph in graph out, so some transformer on a graph that also produces a graph. This way information can be added to the nodes and edges of the graph.
torch_geometric is a pytorch based library that works with graphs that can be used to work with this type of data.
Manual to Massive: Scaling AI Without Losing Your Mind
Sebastiaan den Boer talks about scaling AI content enrichment setup. He uses an example of missing or poor quality data in a webshop.
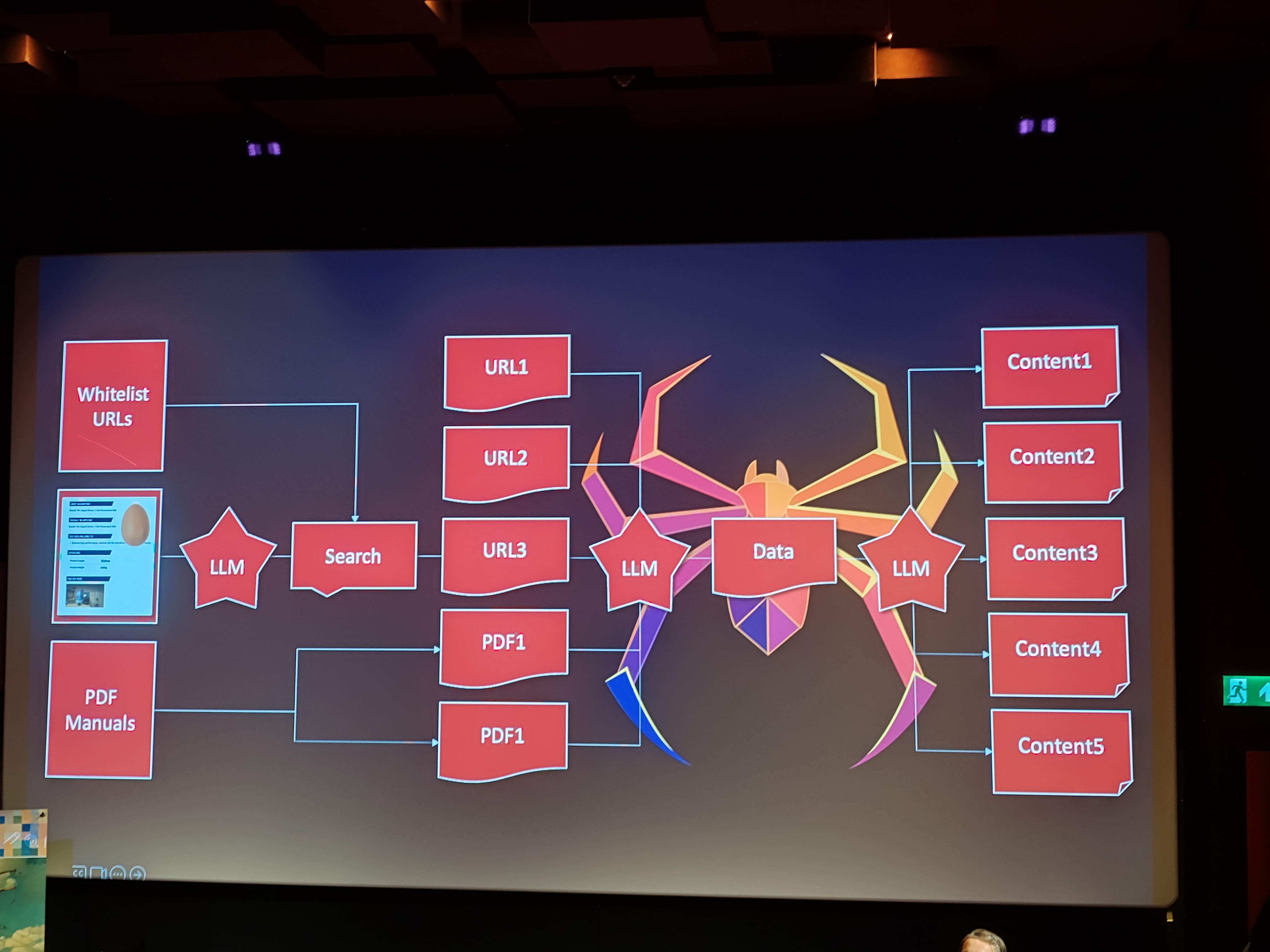
small setup for proof of concept
How do you scale a a solution like this to 9000 records
issues:
- rate limits from google
- limits for how many LLM calls
- prompt management
by using some network tricks like using multiple devices you can get up to ~9000 a day.
fuzzy-json is package for lazy parsing json with issues. This is useful when LLM’s output almost valid json.
cool, now scale to 180K records
issues
- number of api request
- runtime of LLM
- cost of API calls
pdf mining with minerU what package for prompt management?
Make LLM inference go brrr
Maxime LaBonne on x posts the graph that open weight models are catching up with proprietary models.
Advantages of open weights models:
- run them yourself, which means better privacy
- inspect how the model works
- can finetune them
- compress to make them faster
- use community remixes from huggingface hub
If you run models yourself, how can you make them run fast, and memory efficient? There are 3 possible approaches besides just normally loading the model.
tensor parallelism
the bottleneck for model speed is copying data on to the GPU tensor parallelism allows to process a part of the layer on each gpu. This has the advantage of removing memory bottlenecks when serving more users, but interestingly also allows loading larger models on smaller GPUs
quantization
quantization, use a smaller datatype. lower bit floats, or even ints.
paging
allocating memory by computing logical blocks on different GPUs. a waste with this is that when doing multiple prompts, there is going to be similarity with the previous query. you can keep the previous activations by prefix caching. This can greatly improve performance.
Hallucinations and Hyperparameters: Navigating the Quirks of LLMs
Shimmers: building a GenAI indie game
Throughout recent years, building and publishing mobile games as an indie developer has become harder and harder, with increasing user expectations, massive competition, and more regulation to adhere to.
Enter GenAI! Using modern GenAI tools (Midjourney, ChatGPT) for development and art creation, as well as APIs (OpenAI) to quickly integrate generative AI in different parts of your app, one man army indie developers with full time jobs are a thing again.
Jochem talks about integrating genAI in every part of development: architecture, writing the code, generating assets etc. The perception about using ai in the creative community is pretty negative, which might make it harder to market an app made this way.
tenets of development without thought
- outsource everything to LLM
- insert your entire context into your prompts
- let the LLM be architect and developer
- generalize and compartmentalize
- testing and short feedback cycles
think about monetization : revenuecat moving from openai to claude haiku to save money think about privacy/GDPR
From RAG to riches: How LLMs can take enterprise search to the next level
during chunking it’s possible to also add document summary metadata to help during retrieveal
if hallucination is a big problem, you can also just do retrieval without generation.
you can use a synthetic dataset BEIR for evaluating the performance of the entire RAG setup