

Hoogtepunten van aiGrunn 2025
Table of Contents
Ik heb de AI-conferentie in Groningen bezocht, genaamd aiGrunn. Als AI-professional was ik benieuwd waar de lokale AI-scene in Groningen aan werkt. De naam van de conferentie komt van de stad Groningen waar het evenement wordt gehouden, “ai” betekent ook ei in het Gronings, dus er zijn veel verwijzingen naar eieren.
Talks
How AI is helping you back on the road
Yke Rusticus van de ANWB presenteert hoe AI-technieken passen in het diagnosticeren van autoproblemen voor pechhulp. Hij liet verschillende stappen zien in het proces van het diagnosticeren en repareren van een auto waar AI zou kunnen helpen. Van het bepalen of pechhulp nodig was tot het plannen waar de reparatiebusjes naartoe gestuurd moesten worden. Best gaaf om een toepassing van AI in een andere sector dan normaal te zien, ook al lijken de technieken erg op wat ik in mijn eigen werk gebruik.

leermomenten aan het eind
De les om de feedback-loop vroeg op te nemen is er een die ik erg nuttig vind.
Design Patterns for AI Agents in Python
De lezing van Arjan was getiteld “Design Patterns for AI Agents in Python (with Pydantic AI)”, maar hij gebruikte uiteindelijk geen Pydantic AI. In plaats daarvan richtte hij zich op de bredere ontwerppatronen voor AI-agenten. De kern van zijn lezing ging over declaratief versus imperatief programmeren. Hij betoogde dat een declaratieve aanpak zeer geschikt is voor LLM’s, omdat je hiermee het gewenste resultaat kunt definiëren en de LLM de stappen kunt laten uitzoeken om daar te komen. Hoewel de lezing niet was wat ik van de titel had verwacht, was het een goede herinnering aan het belang van fundamentele ontwerpprincipes bij het werken met AI.
Praten tegen een declaratief ontworpen LLM-stroom in het Gronings
Building Interactive AI Vision Tools in the Browser
Mark Redeman gaf een praktische lezing over het bouwen van een interactieve beeldannotatietool die rechtstreeks in de browser draait. Hij demonstreerde hoe je OpenCV gecompileerd naar WebAssembly (Wasm) kunt gebruiken om dit te bereiken. Een belangrijk inzicht was het belang van het optimaliseren van de bibliotheekgrootte; door OpenCV handmatig naar Wasm te compileren, kon hij de grootte verkleinen van 9,8 MB naar slechts 2,1 MB, waardoor het veel geschikter werd voor webapplicaties. Hij wees naar het open-source project GETI als referentie, dat te vinden is op https://github.com/open-edge-platform/geti/. Een van de hoogtepunten was dat hij het meta-model voor segmentatie SAM liet zien. Dit model was redelijk goed in het segmenteren van objecten vanaf een enkel punt.
GPT-NL: Developing a Dutch LLM from scratch
Julio en Athanasios praten over data-acquisitie en het trainen van een LLM vanaf nul. Het doel is om een LLM te hebben met vertrouwde databronnen, in theorie open weights in de Nederlandse taal. Dit LLM moet in staat zijn om taken uit te voeren die het meest relevant zijn voor de Nederlandse taal. Een interessante anekdote was: als je een LLM vraagt om een kinderverhaal te bedenken, zal het hoogstwaarschijnlijk superhelden of cowboys bedenken omdat die frequent zijn in de Amerikaanse cultuur, maar het zou gaaf zijn als het Nederlandse model schippers van de kameleon of jip en janneke zou bedenken. Ik vraag me af of deze aanpak in de toekomst waardevol zal zijn, omdat het moeilijk zal zijn om te concurreren met de techgiganten. Maar als er use-cases zijn waar de Amerikaanse of Chinese modellen niet mogen worden gebruikt, of niet de niche-eigenschappen van een Nederlands-first model bieden, kan het nuttig zijn.
Liar Lair! Assessing the Correctness of LLM Chatbots
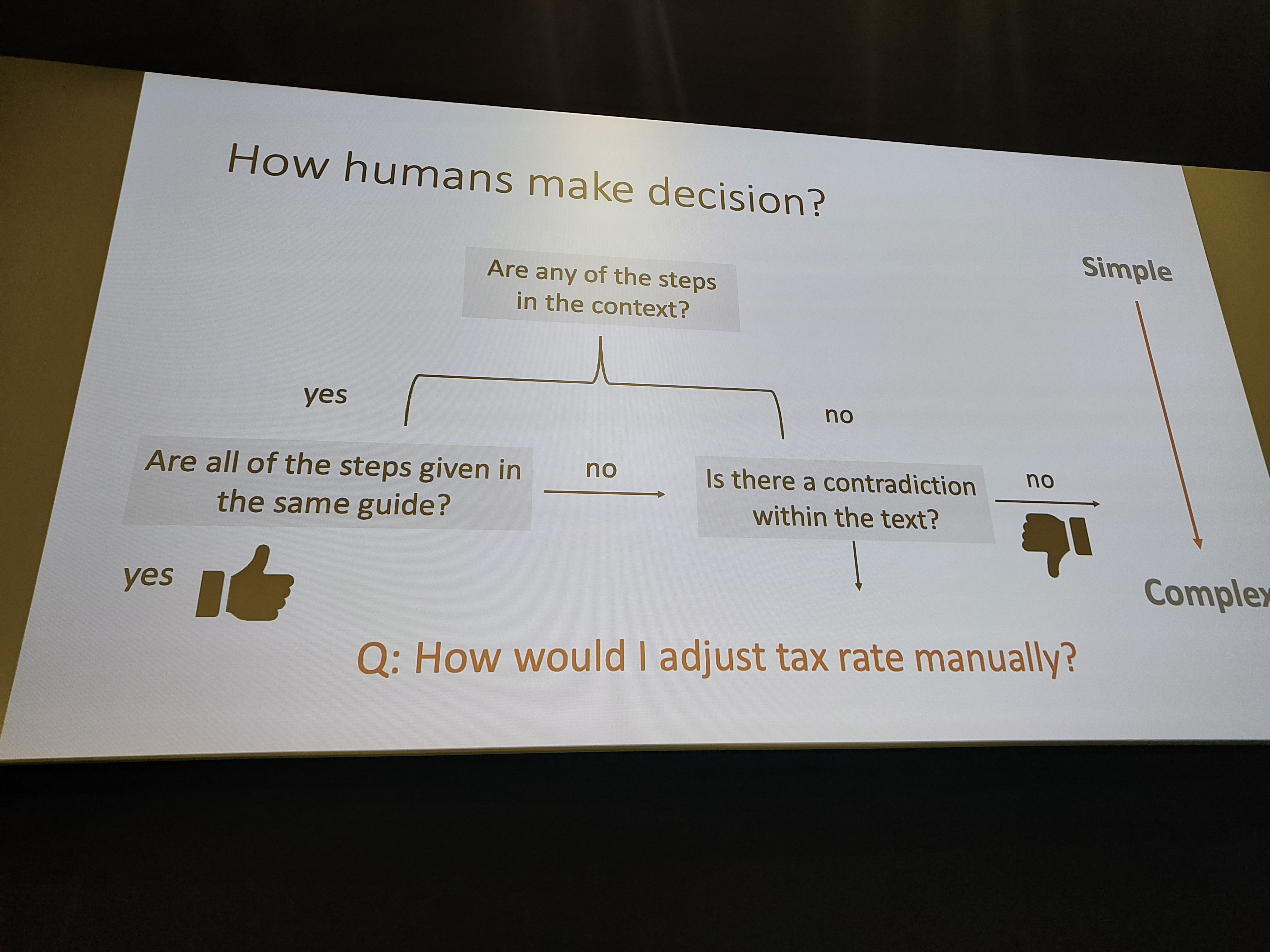
Deze lezing behandelde de uitdagende vraag hoe de juistheid van de output van een LLM-chatbot te beoordelen. De spreker begon met het definiëren van juistheid en verdeelde het in drie componenten: gerelateerdheid, volledigheid en waarheidsgetrouwheid. Waarheidsgetrouwheid werd benadrukt als de meest kritische component.
Een belangrijke conclusie voor mij was de suggestie om te controleren of het gegenereerde antwoord organisatiespecifiek jargon bevat. Als dat zo is, is het waarschijnlijker dat het antwoord is afgeleid van de juiste context. De lezing behandelde ook verschillende uitdagingen bij het beoordelen van de juistheid, zoals wanneer een antwoord correct is, maar niet het best mogelijke antwoord, of wanneer de brondocumentatie verouderd is. Een bijzonder interessant punt was dat een model een correct antwoord kan ‘hallucineren’, wat betekent dat het niet naar enige context verwijst, maar toch feitelijk correct is. Dit maakt het probleem van validatie nog complexer.
Teaching AI to Hunt for Vulnerabilities
Roald Nefs introduceert me aan de term vibe hacking. Hij vergelijkt de LLM-hacking-agent met een varken dat op zoek is naar truffels. Je hebt nog steeds de mens nodig om de truffels op te rapen en te verkopen. Hij toont de architectuur voor een multi-agent-opstelling met één planningsagent en meerdere agenten die tools kunnen gebruiken. Ze werken samen aan een takenlijst om een penetratietest van een doelwit uit te voeren. Deze opstelling was meer een proof-of-concept dan een volledig gerealiseerde oplossing, maar was desondanks interessant.
Some risks include:

De keynote van Michael Biehl was zeer technisch en diepgaand en behandelde traditionele AI toegepast op enkele medische problemen. Het was gaaf om te zien wat een algoritmisch veel eenvoudiger model al kan bereiken, ook al is de statistische analyse na de modeltraining nog steeds vrij complex.
Tot slot was er tijdens het panel een vraag over Europese LLM’s versus de Amerikaanse en Chinese modellen. Het lijkt erop dat de ontwikkeling van Europese modellen behoorlijk achterloopt op de concurrentie. Berco Beute, de gastheer van de dag, deelde een auto-analogie om deze vraag te beantwoorden. De auto die door Amerikanen is ontwikkeld voor een Amerikaanse markt waar benzine goedkoop is, grootte geen probleem is en vervuiling ook niet echt een probleem was. Vervolgens gaven de Japanners ook hun eigen interpretatie aan de auto, waarbij ze veel meer rekening hielden met hun relevante beperkingen in grootte en beschikbaarheid van brandstof. Hij zei dat het Europese ontwerp van LLM’s een vergelijkbaar traject zou kunnen volgen in een veel meer gereguleerde markt, rekening houdend met milieu- en energiebeperkingen.
Conclusie
Het was leuk om deze conferentie weer bij te wonen. Het helpt om op de hoogte te blijven van de nieuwste technologie en te zien wat anderen in het veld doen. De ontnuchterende opmerkingen van Michael Biehl over de AI-hype en hoe de interesse in AI komt en gaat, waren ook welkom. Ik kijk ernaar uit om volgend jaar weer te bezoeken.